The Data Story of the SC EPSCoR Research Expertise Profile Database
By April Heyward, MRA, Program Manager
SC EPSCoR State Office
The SC EPSCoR Research Expertise Profile Database was launched with the aims of being a repository of research expertise and facilitator of collaborations across EPSCoR jurisdictions. The database contains close to 300 research expertise profiles representing the Alaska, Arkansas, Guam, Hawaii, Maine, South Carolina, and Wyoming EPSCoR jurisdictions. The data is promising as it indicates other jurisdictions are seeking collaborations with South Carolina researchers. In this dual-purpose sharing moment, you will learn more about the Research Expertise Profile Database and receive a behind-the-scenes look at how Data Science and Machine Learning Algorithms informs the SC EPSCoR Program about researchers.
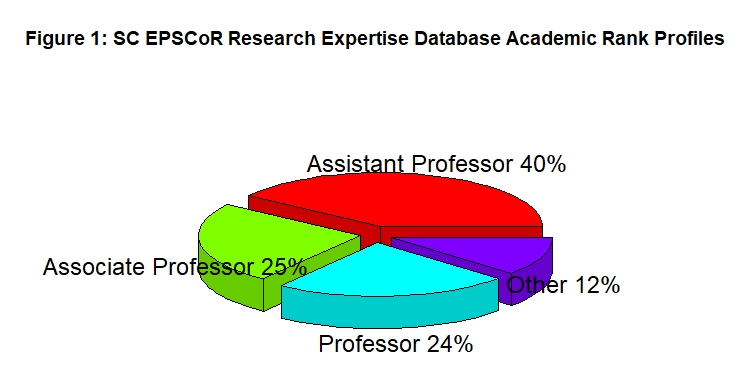
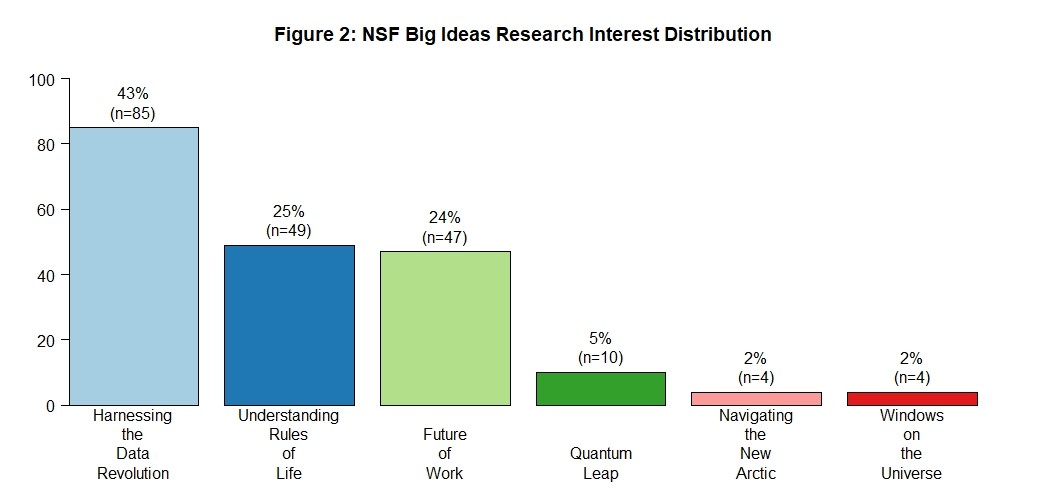
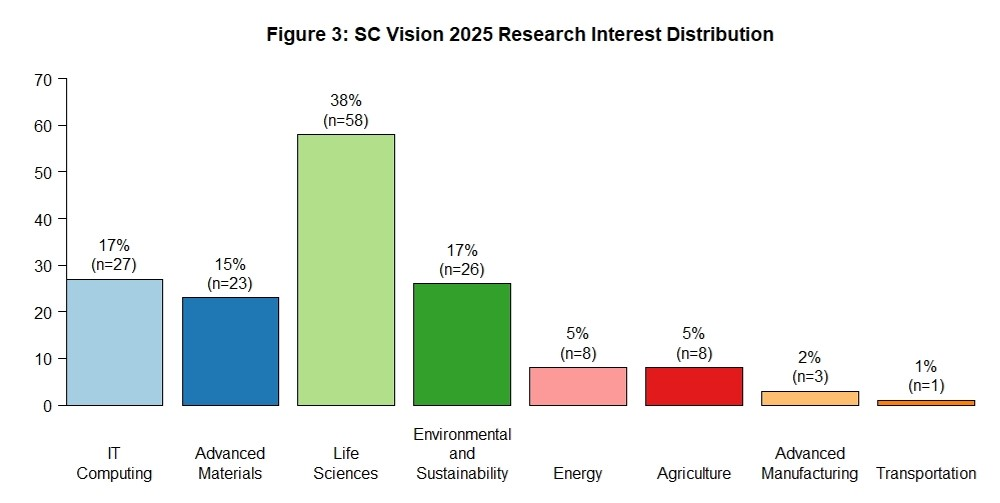
Any Data Scientist can attest to the hours, days, and weeks it takes to wrangle data in structured and unstructured formats to a tidy format before the start of the data analysis, modeling, and visualizations stages. Thanks to Dr. Hadley Wickham’s tidyverse R package (plus a host of other R packages and functions), the data story of the SC EPSCoR Research Expertise Profile Database begins. Assistant Professors are the largest group of research expertise profiles in the database at 40% then Associate Professors, Professors, and Others (e.g., Research Faculty, Clinical Faculty, Adjunct Faculty, Directors, STEM and Industry Professionals) in rank order. See Figure 1: SC EPSCoR Research Expertise Database Academic Rank Profiles. Please note rounding differences derived from dummy coding are represented in figures. Data analysis revealed the top 3 NSF Big Ideas research interests are Harnessing the Data Revolution, Understanding the Rules of Life, and Future of Work at the Human Technology Frontier. The top 3 SC Vision 2025 research interests are Life Sciences, IT Computing, and Advanced Materials. See Figure 2: NSF Big Ideas Research Interest Distribution and Figure 3: SC Vision 2025 Research Interest Distribution.
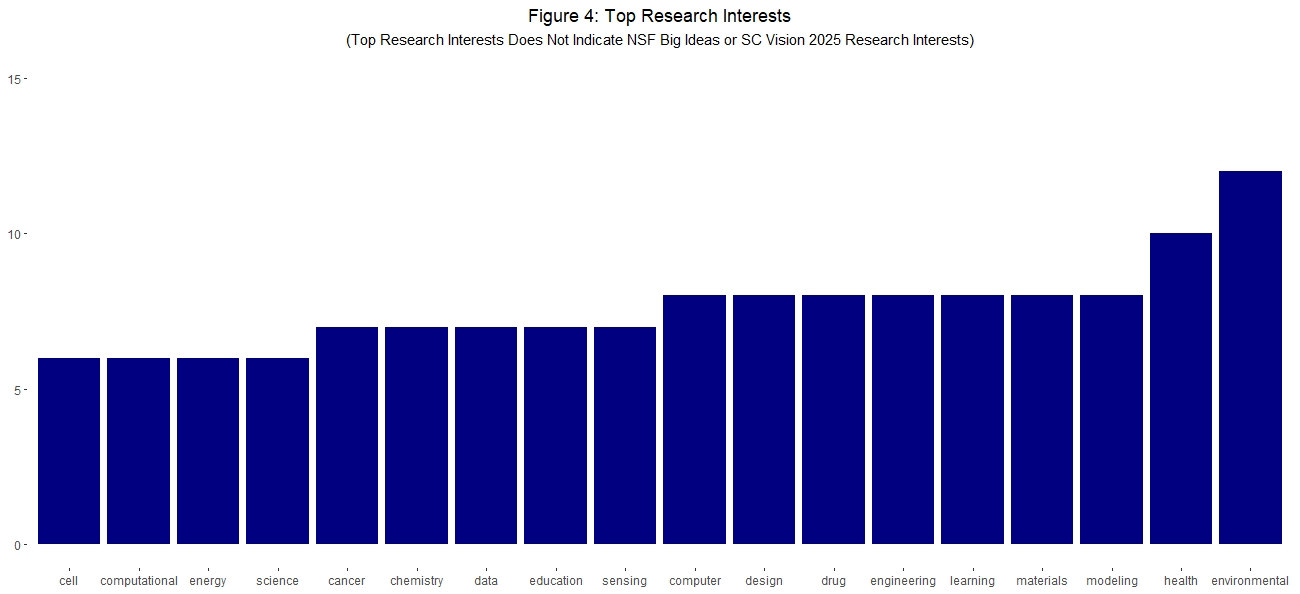
The next aim was to employ Machine Learning algorithms (e.g., natural language processing, text mining, SnowballC, RWeka, tidytext, VCorpus, Bigrams) to analyze the text of research interests and research statements submitted in the database. Researchers have the option of providing their top three research interest keywords (beyond the NSF Big Ideas and SC Vision 2025 research interests) and a brief statement/description of their research. The output of the three research interest keywords is presented in three columns in the database and were combined into a text file for cleaning in preparation for text mining. Some of the top research interest keywords that emerged are environmental, health, modeling, materials, engineering, computer, data, chemistry, and computational. The brief research statements were combined into a text file and cleaned in preparation for text mining. Some of the top research statement words are data, systems, analysis, health, computational, environmental, and modeling. See Figure 4: Top Research Interests and Figure 5: Top Words in Research Statements. Bigrams are two words paired and were created to identify high frequency of paired words in research statements. The top bigrams are data analysis, data science, heat transfer, machine learning, and transition state. The results of the data analysis informs the SC EPSCoR Program of the distribution of usage of the database and provides a collective view of what researchers are interested in the most.
If you are not registered in our research expertise profile database, please take a moment to complete your research expertise profile. Please visit and bookmark our research expertise profile database if you are seeking collaborations.
April 2020